
🎧 Listen to the Download
Hey everyone! Guess what? We’ve made it to the 10th edition of the DevGyan Download! It’s been an incredible journey sharing insights on data and tech. Thanks a bunch for your support.
This week at Download, we’re diving into how automated pipelines are cutting down on latency, and how new tools are turning raw data into actionable insights. If you’re someone who wants to streamline operations or use analytics to grow your business, you’re in the right place. We will also look at how copilot is enabling text-to-analytics transformations.
Checkout Synoposis, the LinkedIn newsletter where I write about the latest trends and insights for data domain. Download is the detailed version of content covered in Synopsis.
Trigger‑Happy: How Real‑Time Jobs Are Replacing Cron in Lakeflow
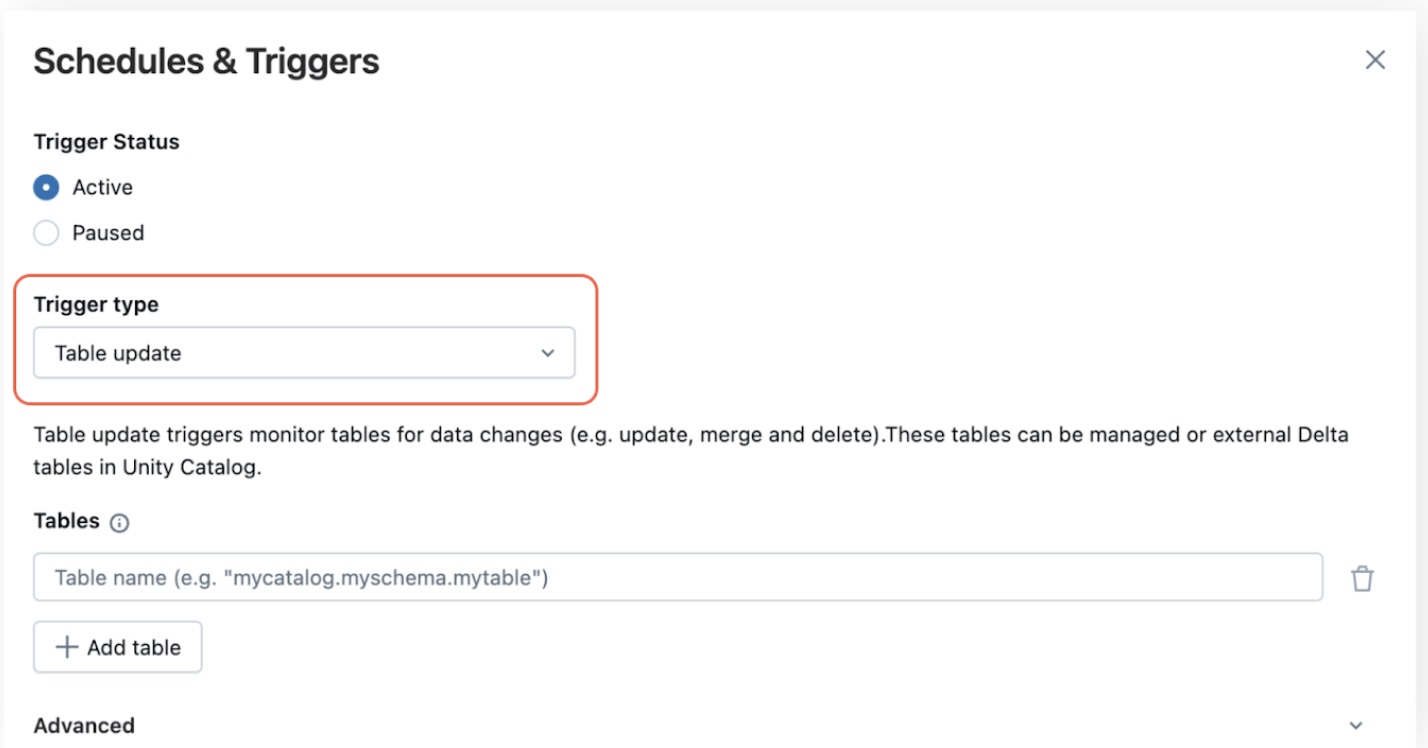
Databricks has rolled out table update triggers for Lakeflow Jobs, letting you fire pipelines automatically whenever a Unity Catalog table is written to. Instead of guessing with cron schedules, your jobs launch instantly on data arrival, cutting latency, lowering compute costs, and keeping dashboards fresh. These triggers support single‑table or multi‑table modes, advanced timing options (min‑time between runs, wait‑after‑last change), and inherit the same observability and lineage features as file‑arrival triggers.
Key Features
- Immediate Job Start – Runs as soon as data is added or updated.
- Flexible Scheduling – Single or all‑tables update, with optional delay controls.
- Built‑in Observability – Table commit timestamps exposed to downstream tasks.
- Automated Lineage – Unity Catalog shows read/write relationships.
- Scale‑Friendly – Ideal for high‑volume, cross‑time‑zone pipelines.
My Take
From a data‑engineering lens, these triggers are a game‑changer. By decoupling job execution from rigid cron windows, teams gain true event‑driven orchestration, reducing idle compute and eliminating stale‑data drift. The seamless integration with Unity Catalog’s lineage and snapshot parameters ensures consistency across tasks, a critical factor when scaling pipelines across many services. Overall, table update triggers empower autonomous, self‑service data teams to build responsive, cost‑efficient workflows that keep insights real‑time.
AI‑Powered Reports: Power BI’s Copilot Just Got Smarter
Microsoft has just upgraded Power BI’s Report Copilot, making AI‑driven report creation faster, smarter, and more collaborative. The new experience, live in the Power BI service (Desktop rollout slated for Nov 2025), lets you build entire report pages in seconds, tweak visuals with fine‑grained control, and iterate with Copilot instead of starting from scratch each time. The Copilot now “understands your data and intent more deeply than ever,” turning natural‑language prompts into instant visual insights. To unlock the feature, work in a Copilot‑enabled workspace (Fabric or Premium P1+ capacity) and ensure your admin has enabled Copilot in Microsoft Fabric. For details, see the official Microsoft blog post: Introducing Improvements to the Report Copilot in Power BI.
Key Highlights
- Instant page generation – Create full report pages with a single prompt.
- Enhanced visual intelligence – Copilot recommends richer visuals and auto‑adjusts layouts.
- Collaboration & iteration – Work alongside Copilot, refine existing reports, and use undo/redo.
- Workspace requirements – Must be in a Copilot‑enabled workspace (Fabric or Premium P1+).
- Desktop rollout – Available in Power BI Desktop by November 2025.

My Take
From a data‑tech perspective, this upgrade signals a leap toward augmented analytics. The Copilot’s deeper intent understanding reduces the cognitive load on analysts, letting them focus on insight rather than format. The integration of undo/redo and flexible editing ensures that creative freedom doesn’t come at the cost of control—a critical balance for enterprise deployments. Overall, the update positions Power BI as a more intuitive, AI‑centric platform ready to democratize data storytelling across teams.
Spark Meets Snowflake: A One‑Stop Data Platform
Snowflake’s latest release, Snowpark Connect, lets developers run Spark workloads—DataFrames, SparkSQL, and more—directly inside Snowflake’s compute engine. By embedding a Spark Connect–compatible server, the platform eliminates the need for a full Spark cluster. Clients send logical query plans over gRPC, which Snowflake translates into optimized Snowpark or SQL operations, then executes with its vectorized engine.
Key Highlights
- Unified Execution – Spark jobs execute on Snowflake, removing cross‑cluster data movement and reducing latency.
- High Compatibility – Passes over 85 % of SparkSQL, HiveSQL, and ANSI SQL tests.
- Cost & Complexity Savings – No separate Spark clusters; simpler scaling and governance.
- AI‑Driven Testing – Engineers used AI‑generated workloads to stress‑test edge cases.

Snowpark Connect is a public preview; Snowflake plans to expand feature support and performance. It underscores the company’s commitment to open standards while providing enterprise‑grade security and scalability.
from pyspark.sql import SparkSession
spark = (
SparkSession.builder
.remote("sc://<your_snowflake_account>.snowflakecomputing.com") # Spark Connect endpoint
.appName("SnowparkConnectDemo")
.getOrCreate()
)
df = spark.createDataFrame(
[(1, "Oliver", 500), (2, "Tom", 400), (3, "Michelle", 800)],
["id", "name", "cost"]
)
df.createOrReplaceTempView("employees")
high_earners = spark.sql("SELECT name, cost FROM employees WHERE cost > 500")
high_earners.show()
My Take
From a data‑engineering perspective, Snowpark Connect removes a major friction point—moving data between Spark clusters and Snowflake. By serializing logical plans and leveraging Spark’s Catalyst optimizer, it maintains familiar Spark APIs while harnessing Snowflake’s performance engine. The 85 % compatibility score is promising, but real‑world workloads will reveal any gaps. Overall, this integration streamlines pipelines, reduces operational overhead, and accelerates AI initiatives—all without sacrificing security or governance.
Patience Powered AI: How SentinelStep Gives Agents a Sense of Timing
Modern LLM agents can debug code and book travel, but they struggle with simple waiting tasks—monitoring emails or price drops. Microsoft Research introduced SentinelStep, a workflow wrapper that lets agents perform long‑running monitoring without exhausting context or burning tokens.
How SentinelStep Works
- Dynamic polling: guesses an optimal interval per task (e‑mail vs. quarterly earnings) and adapts in real time.
- Context management: saves state after each check to prevent overflow.
- Co‑planning interface in Magentic‑UI: users get a pre‑filled multi‑step plan that the orchestrator executes with the most suitable agent (web, code, MCP).
Evaluation
Microsoft built SentinelBench, a synthetic web environment with 28 configurable scenarios (GitHub Watcher, Teams Monitor, Flight Monitor).
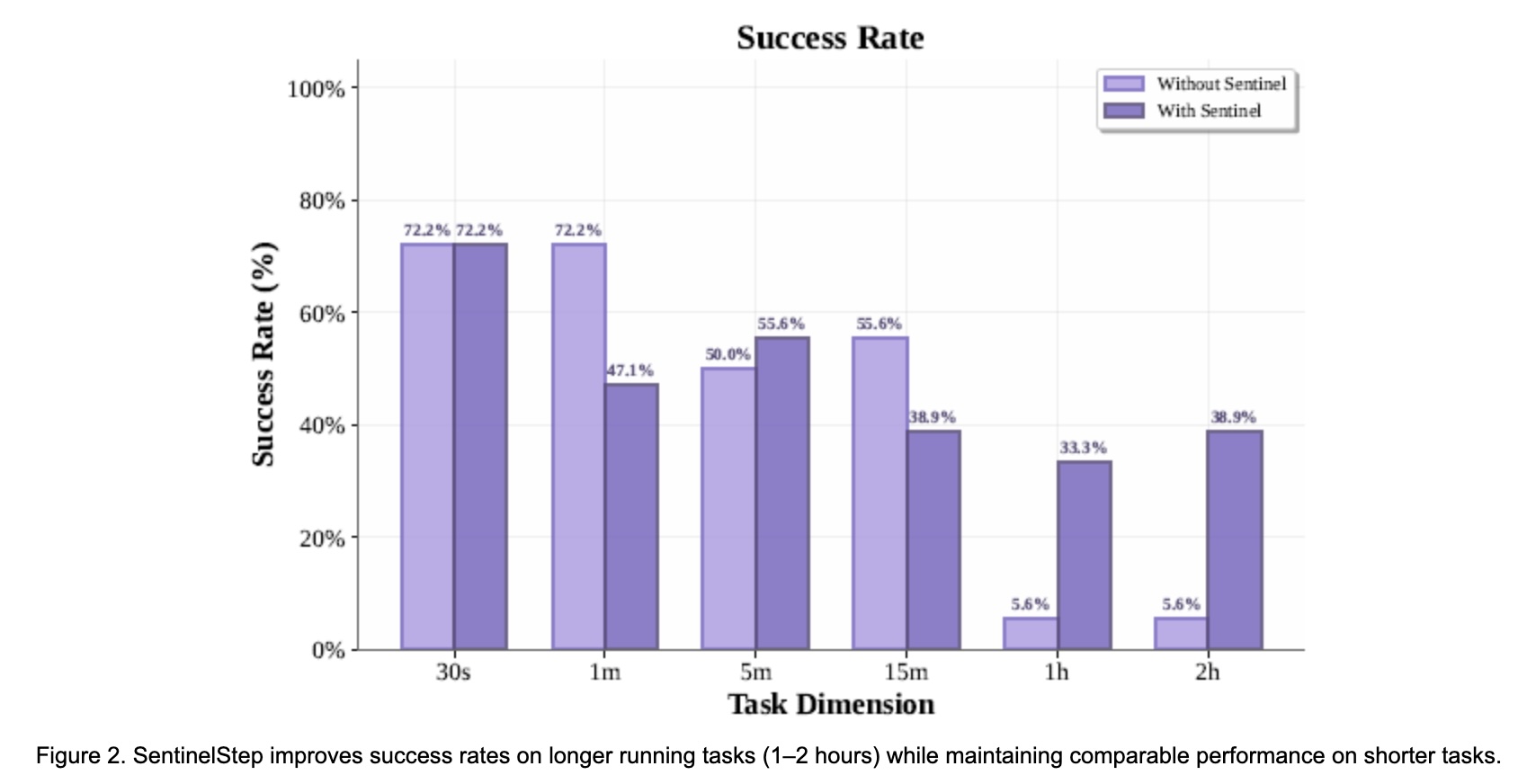
- Short tasks (≤1 min) show similar success with or without SentinelStep.
- Long tasks: reliability jumps from ~6 % to ~33 % at 1 h, and ~39 % at 2 h.
- SentinelBench also allows fine‑tuning of polling intervals and provides logs that help diagnose why an agent missed a target.
- The open‑source release on GitHub means teams can experiment with different agent back‑ends and integrate SentinelStep into existing pipelines.
- Benefits
- Fine‑tune polling intervals
- Log and diagnose missed events
- Easy integration with existing agents
My Take
From a data‑engineering lens, SentinelStep tackles two core bottlenecks: polling inefficiency and context overflow. By quantifying polling intervals and preserving state, it turns fragile monitoring into a robust, resource‑efficient routine—essential for any “always‑on” AI assistant.
For data scientists, the ability to simulate monitoring workloads with SentinelBench simplifies performance benchmarking and helps validate scaling strategies.
In short, SentinelStep is a practical leap toward AI that can wait patiently and act precisely.
Final Thoughts
We are witnessing the final phase of the transition from manually managed, time-based data systems to event-driven, autonomous workflows. Databricks’ auto-triggers and Snowflake’s Snowpark Connect collectively eliminate the historical lag, complexity, and resource waste inherent in traditional ETL/ELT. Engineers can now build faster, cheaper pipelines by focusing on logical plans over cluster management.
Crucially, this speed is matched by a new layer of augmented analytics. Tools like Power BI’s smarter Copilot democratize data storytelling by lowering the barrier to entry, while Microsoft’s SentinelStep tackles the fundamental challenge of building reliable, patient AI agents.
The key takeaway for any leader or practitioner is to see these advancements not as isolated products, but as components of an Intelligent Data Flywheel. Automation creates speed, speed enables real-time insights, and real-time insights are delivered by intuitive, AI-powered tools. Success now hinges on adopting this convergence responsibly, ensuring speed and innovation are balanced with robust security and data governance.