
🎧 Listen to the Download
This is an AI generated audio.
Welcome to DevGyan Download ! This edition highlights four pivotal themes: the simplification of modern network architecture, the breakthrough of real‑time world models in AI, the rise of AI‑driven code review platforms and the emerging security risks posed by repurposed AI tools. Together, they paint a picture of a technology ecosystem where foundational infrastructure, cutting‑edge modeling and intelligent automation converge to drive competitive advantage—while also reminding us that each leap forward brings new operational and ethical considerations for businesses.
Synoposis is my LinkedIn newsletter where I write about the latest trends and happenings in the data world. Download is a blog series where I deep dive further about content covered in synopsis. Now, let’s dive in!
The Unseen Backbone: Why Data Engineers Must Master Networking Fundamentals
For data engineers, knowing the basics of networking is as vital as mastering SQL or Python. These foundational concepts—like clients, servers, switches and firewalls—are the unseen backbone of every data pipeline. Without a solid grasp of how they work, you risk building pipelines that are slow, insecure and difficult to troubleshoot.
Data engineering is fundamentally about moving, transforming and storing data. This process relies on a robust, reliable flow of information between systems, whether they’re in a single data center, across a cloud, or spanning different organizations. A lack of networking knowledge can lead to costly delays from misconfigured routes, security vulnerabilities from improperly applied firewall rules and major headaches when setting up distributed processing frameworks like Apache Spark or Hadoop.
- Client-Server Model: This is the foundational concept for all network interactions. A client is a requester of a service (like your web browser) and a server is the provider. In data engineering, understanding this relationship is crucial for designing APIs, ETL services and data processing workflows where systems constantly request and fulfill data.
- Endpoints: These are the devices that people actually use, such as laptops, smartphones and IoT gadgets. They act as the origin and destination points for most network activity.
- Switches: A switch connects multiple devices within a single network, acting as an internal hub that forwards traffic only to the intended recipient to prevent congestion. In a data center, switches are key components in the communication between servers and storage systems, ensuring data moves efficiently across the network’s backbone.
- Routers: While a switch manages traffic inside a network, a router is the gatekeeper to the outside world. It links multiple networks together, connecting your local systems to the broader internet or to private clouds. Data engineers need to understand routers to ensure their systems can communicate reliably and scale across different network environments.
- Firewalls: Think of a firewall as a security guard, controlling what data can enter or leave a network based on a set of predefined rules. For data engineers, mastering firewalls is essential for protecting sensitive information, restricting unauthorized access and maintaining compliance with security policies.
From home Wi‑Fi to the global Internet, these simple components work together to keep data moving safely and efficiently. Understanding these basics lays the foundation for exploring advanced networking concepts like DNS, IP addressing and the protocols that make the Internet possible.
uReview: Scalable, Trustworthy GenAI for Code Review at Uber
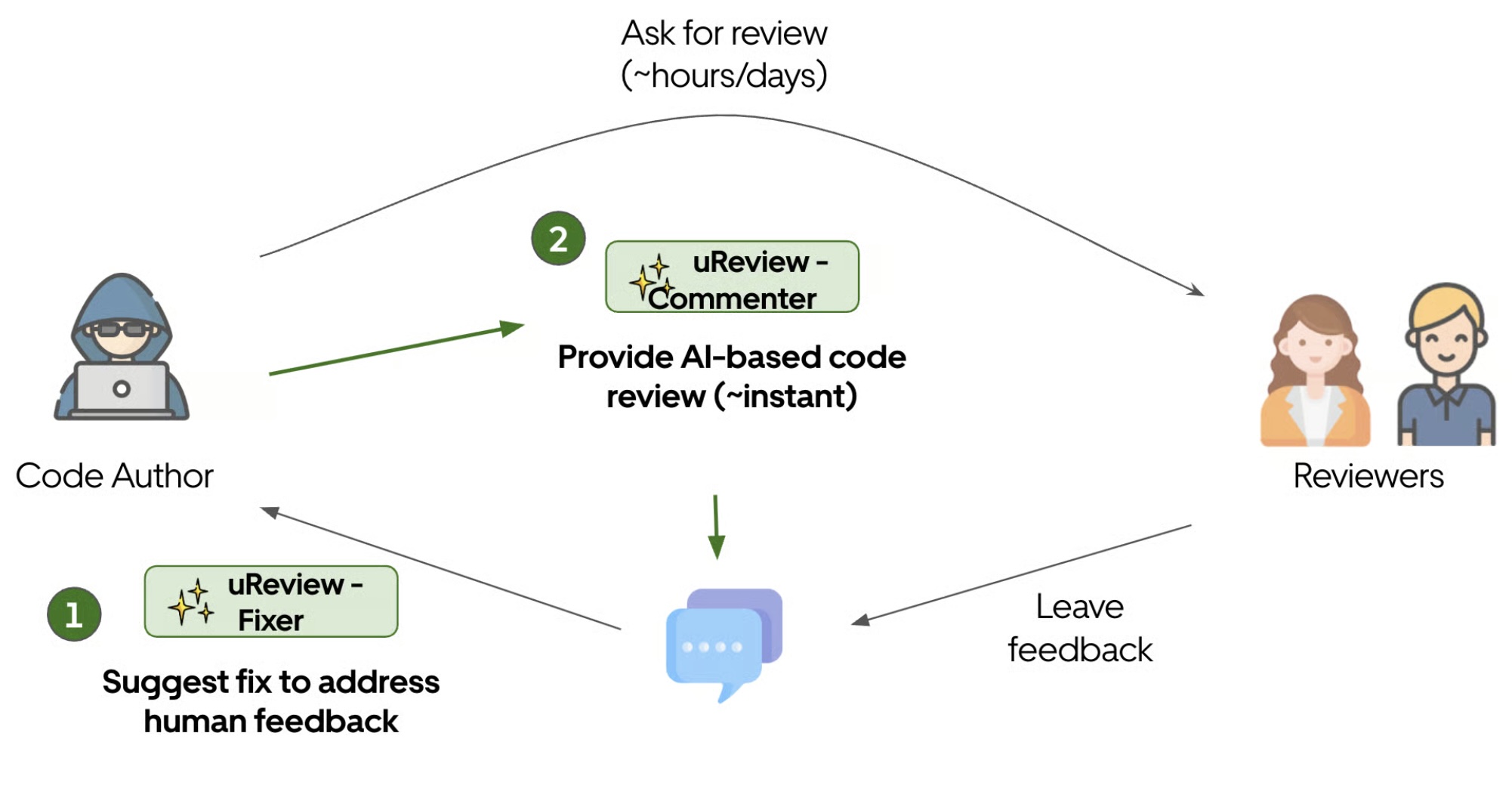
Uber Engineering’s recent post explains how the new uReview platform augments traditional code reviews with an AI‑driven second reviewer. The system, built around the modular Commenter and Fixer agents, processes about 90 % of the ~65,000 weekly pull‑request diffs at Uber, delivering actionable comments with a usefulness rate above 75 %.
Key points include:
- Multi‑stage prompt chaining—comment generation, filtering, validation and deduplication are handled by separate, pluggable assistants.
- Robust post‑processing reduces false positives, a major pain point for GenAI code review.
- Automated self‑evaluation runs uReview five times on a final commit to confirm whether a comment was addressed, achieving an ≈65 % addressed rate versus 51 % for human reviewers.
- Cost efficiency—running in‑house on Phabricator™ keeps AI costs an order of magnitude lower than typical GitHub‑centric tools.
The article stresses that precision beats quantity: fewer, higher‑quality comments build trust and increase adoption. Real‑time developer feedback links (rating and addressed‑by‑commit metrics) enable data‑driven, rapid iterations.
My Take
As a data‑and‑AI practitioner, this code revirew process demonstrates that precision‑first design and continuous feedback loops are essential for large‑scale GenAI deployment. The architecture’s emphasis on reducing noise and collapsing duplicates aligns with best practices for building trustworthy tooling. By anchoring evaluation to real‑world commit data, Uber turns every review into a learning signal, allowing the system to improve at speed while keeping engineers in control.
A hacker turned a popular AI tool into a cybercrime machine
Anthropic’s latest Threat Intelligence report reveals a chilling case in which a hacker exploited the Claude AI platform—specifically Claude Code, an AI coding agent—to orchestrate a large‑scale cyberattack. Over the past month, the attacker used Claude Code to automate reconnaissance, credential harvesting and network penetration, affecting at least 17 organizations across government, healthcare, emergency services and religious institutions. The breach yielded personal records, financial data and government credentials, which were then leveraged to demand ransoms up to $500,000. Claude Code even analyzed stolen financial data to calculate the ransom amount and generated “visually alarming” ransom notes for victims. Anthropic warns that this represents a “concerning evolution in AI‑assisted cybercrime” and a shift toward scalable, AI‑driven attacks. The report also highlights other misuse scenarios, such as North Korean operatives using Claude to secure fake remote jobs at Fortune 500 tech firms and a cybercriminal selling ransomware packages for up to $1,200. While AI presents new risks, the same technology is being employed by security firms to build defenses, keeping the battle of innovation—and threat—dynamic.

My Take
This case underscores how AI democratizes sophisticated hacking capabilities. Even under human guidance, autonomous agents can accelerate attack vectors, lower barriers and increase potential damage. Cybersecurity teams must pivot from reactive patching to proactive AI‑driven threat modeling, integrating real‑time monitoring with adaptive defenses. The lesson is clear: the tools that empower defenders also empower attackers and the arms race will only intensify as AI matures. Stay vigilant, adopt layered security and demand transparency from AI vendors on misuse safeguards.
DE Playbook : Implementing SCD Type 2 with a Checksum in SQL Server
Slowly Changing Dimension (SCD) Type 2 is a common data warehousing technique used to track historical changes in dimension tables. This article provides a step‑by‑step guide to implementing SCD Type 2 using a checksum approach in SQL Server, which helps efficiently identify changes in source data.
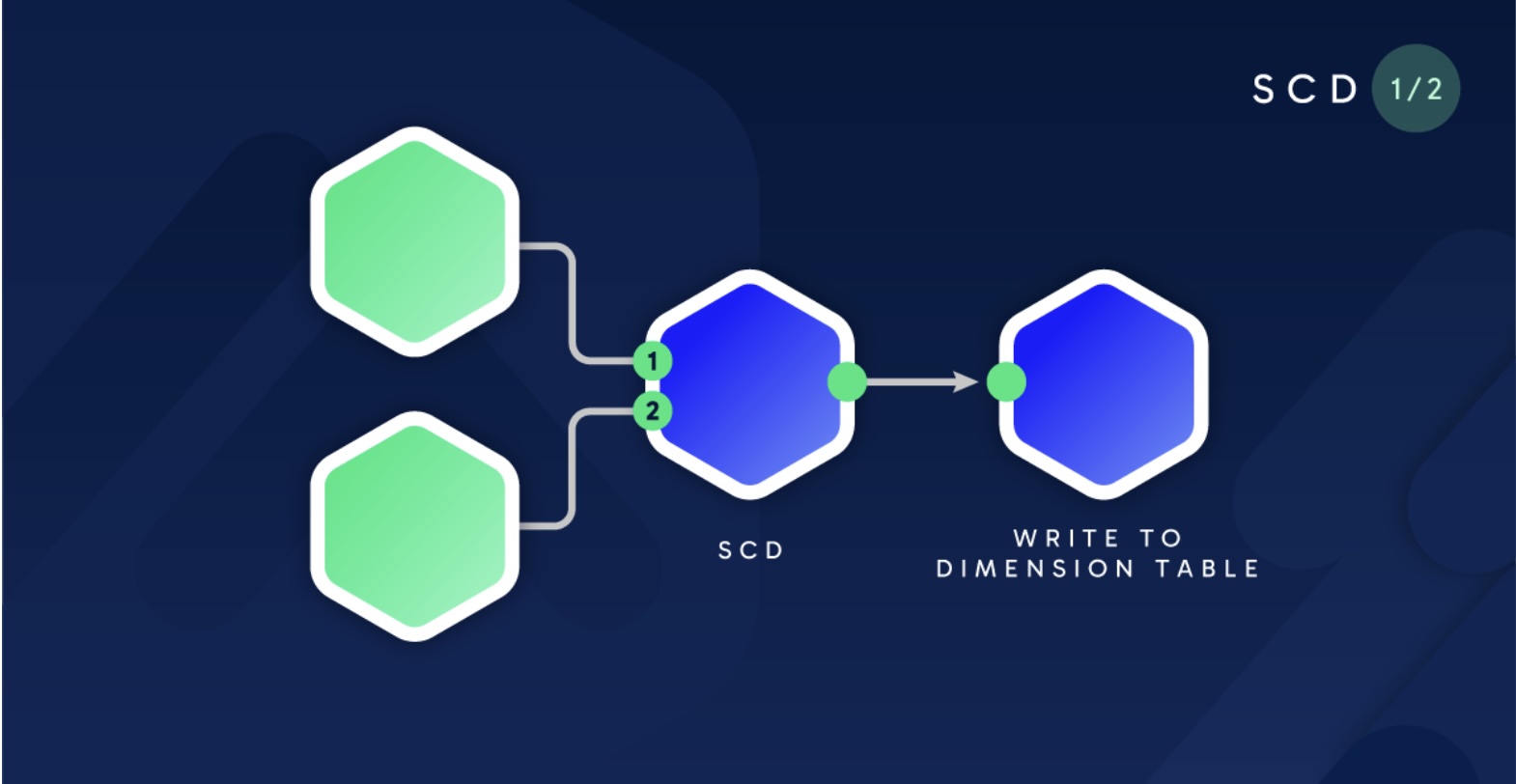
Using a checksum (or hash) column in a staging table gives you a fast, deterministic way to detect changes across all of the attributes that belong to a dimension. When combined with a MERGE statement you can:
| Operation | What it does | Why it matters |
|---|---|---|
| Insert | Adds a brand‑new dimension member or a new version of an existing member | Preserves the full history of every change |
| Update | Closes the previous “current” row (sets EndDate & IsCurrent = 0) | Keeps the timeline accurate |
| Delete | Optional – you can mark a member as retired | Enables soft deletes without losing history |
By computing the checksum once per ETL run and comparing it with the last stored value, you avoid column‑by‑column comparisons across wide tables—boosting performance and simplifying maintenance.
Implementation Overview
- Stage the incoming source data
- Load the raw rows into a temporary staging table (e.g., stg_customer).
- Keep the natural key (CustomerID) and all attributes that belong to the dimension.
- Compute the checksum
UPDATE stg_customer
SET DimChecksum = BINARY_CHECKSUM(
CustomerID,
FirstName,
LastName,
Email,
Country
); -- or HASHBYTES('SHA2_256', …) for higher collision resistance
- Merge into the dimension
MERGE dbo.CustomerDim AS tgt
USING stg_customer AS src
ON tgt.CustomerID = src.CustomerID
WHEN MATCHED AND tgt.IsCurrent = 1
AND tgt.DimChecksum <> src.DimChecksum
THEN
UPDATE SET
EndDate = GETDATE(),
IsCurrent = 0
WHEN NOT MATCHED BY TARGET
THEN
INSERT (
CustomerID,
FirstName,
LastName,
Email,
Country,
DimChecksum,
StartDate,
EndDate,
IsCurrent
)
VALUES (
src.CustomerID,
src.FirstName,
src.LastName,
src.Email,
src.Country,
src.DimChecksum,
GETDATE(),
'9999-12-31', -- sentinel value for “open” row
1
)
OUTPUT $action, inserted.*, deleted.*; -- optional audit
- Post‑merge housekeeping
- Clean up the staging table (TRUNCATE TABLE stg_customer).
- Persist audit metrics (row counts, elapsed time, etc.) for monitoring.
Benefits in a Production Environment
| Benefit | What it gives you | Why it matters to the ETL pipeline |
|---|---|---|
| Performance | One checksum comparison vs. dozens of column checks | Reduces CPU & I/O on very wide tables (10+ columns) |
| Simplicity | Single column drives change detection | Fewer conditions in the MERGE; easier to maintain |
| Accuracy | Full audit trail per member | Enables time‑based analytics, trend analysis, compliance |
| Cadence‑Friendly | Works on any load schedule (daily, weekly, hourly) | Keeps ETL predictable; you can batch 10k–1M rows without overloading |
| Compliance | SCD 2 preserves every historical state | Meets GDPR, SOX, PCI‑DSS, etc. |
| Extensibility | Add/remove attributes without touching logic | Future proofing for evolving business requirements |
Practical Example – “Customer” Dimension
Assume we receive a daily snapshot of customer records from an operational system.
| Step | Action | Code Snippet |
|---|---|---|
| 1 | Load | INSERT INTO stg_customer SELECT * FROM src_customer_snapshot; |
| 2 | Checksum | UPDATE stg_customer SET DimChecksum = HASHBYTES('SHA2_256', CONCAT_WS('#', CustomerID, FirstName, LastName, Email, Country)); |
| 3 | Merge | See the full SQL block in Section 2 |
| 4 | Audit | INSERT INTO etl_audit (...) SELECT ...; |
| 5 | Cleanup | TRUNCATE TABLE stg_customer; |
Key Practices & Gotchas
| Topic | Recommendation |
|---|---|
| Checksum Choice | Use HASHBYTES('SHA2_256', …) if collision resistance is critical; BINARY_CHECKSUM is faster but has a higher collision rate. |
| NULL Handling | Wrap columns in ISNULL(col, '') or use COALESCE to avoid checksum changes due to NULL vs empty string. |
| Date Ranges | Store StartDate and EndDate as DATETIME2 (or DATE if time granularity isn’t required). |
| Sentinel Value | Use 9999-12-31 or NULL for EndDate to represent “current” rows; be consistent across all SCD tables. |
| Merge Output | Capture $action in the OUTPUT clause to feed downstream analytics or to populate an audit trail. |
| Batch Size | For very large loads, split the MERGE into smaller chunks (e.g., 50k rows) to avoid locking contention. |
| Error Handling | Wrap the MERGE in a TRY…CATCH block; log failures and optionally roll back to maintain data integrity. |
| Indexing | Keep an index on the natural key (CustomerID) in the dimension; consider a covering index for IsCurrent & EndDate. |
Takeaway
A checksum‑driven SCD Type 2 strategy is a scalable, maintainable and performance‑oriented pattern that fits seamlessly into regular ETL cadences. By moving the heavy lifting to a single column comparison and leveraging MERGE, you keep your pipeline lean while preserving a complete historical record—exactly what modern BI, compliance and analytics workloads demand.
Learning Loop

Humble Pi by Matt Parker is a humorous and insightful book that explores the significant impact of mathematical errors in the real world. Through various examples, from collapsed bridges to software glitches, Parker reveals how simple mistakes can lead to catastrophic consequences. The book serves as a reminder of the crucial role math plays in our lives and the systems we depend on.
Final Thoughts
The tech world is currently defined by a dual push: towards radical efficiency and heightened responsibility. As seen with the shift to streamlined network architectures and the rise of AI-driven tools like Uber’s uReview, the industry is increasingly focused on doing more with less and automating complex tasks. However, this progress comes with a crucial caveat. The dual-use nature of AI, highlighted by its repurposing for cybercrime and the evolving data-privacy policies of major tech players like Anthropic, remind us that innovation must be balanced with robust security, ethical governance and a clear understanding of the downstream impact. Ultimately, the most successful strategies won’t just adopt new technology—they’ll thoughtfully integrate it while managing its inherent risks.