
🎧 Listen to the Download
This is an AI generated audio.
Welcome to first edition of DevGyan Download ! I started my journey when business intelligence tools like Cognos, OBIEE, Informatica, and Business Objects gained popularity across industries, driven by SQL. My computer science degree provided a strong foundation in data-related tools and languages. I’ve worked with talented individuals in data and I am eager to share my knowledge on advanced analytics, data engineering, and related topics. In this two-part series, DevGyan Synopsis & Download, I’ll curate content based on my experiences and recent insights from online sources.
Synoposis is my LinkedIn newsletter where I spill the beans on the latest trends and happenings in the data world. Download is a blog series where I deep dive into specific tools, technologies and concepts that I have been exploring lately.
My Philosophy
As a big fan of tech legends like Steve Wozniak (Woz), I believe in a mindset that’s always been my driving force: learning, sharing, and growing as a community.
For me, it’s the engineering, not the glory, that’s really important and If you love what you do and are willing to do what it takes, it’s within your reach. - Steve Wozniak
Why This Newsletter?
First, welcome to the first edition of DevGyan Download! With all the information we process daily and create content around specific areas, it can be tough to understand the outcomes and implications. DEV can mean different things to different people— a Developer, Data Enabler, Data Engineering Veteran, you pick your version of what Dev means to you. And “Gyan” is a Sanskrit word that means “to know of” or “understanding of.” Goal is to save you time and help you stay ahead of the curve. Hope you find it a good read !
Big Picture
Across a rapidly evolving tech landscape, business leaders are increasingly focused on how data, observability, and AI‑driven tools can be leveraged to accelerate decision‑making, reduce operational friction, and unlock new revenue streams. From modernizing data pipelines with incremental loading strategies and next‑gen frameworks like SQLMesh, to harnessing low‑code LLMs that let non‑technical teams prototype quickly, the trend is clear: agility and transparency are the new competitive advantages. Coupled with standardized observability via OpenTelemetry and real‑time collaboration tools that cut context‑switching, these innovations collectively empower organizations to iterate faster, maintain higher quality, and extract clearer insights from their data assets.
SQLMesh: A Next-Gen Data Engineering Tool and Its Competitors.
SQL Mesh is an open-source data transformation framework designed to streamline and optimize the development, testing, and deployment of data pipelines. Developed by engineers with experience at leading tech firms, SQLMesh focuses on providing correctness, efficiency, and advanced developer tooling for data teams. It works on top of modern data warehouses and integrates with major orchestration frameworks like Airflow.
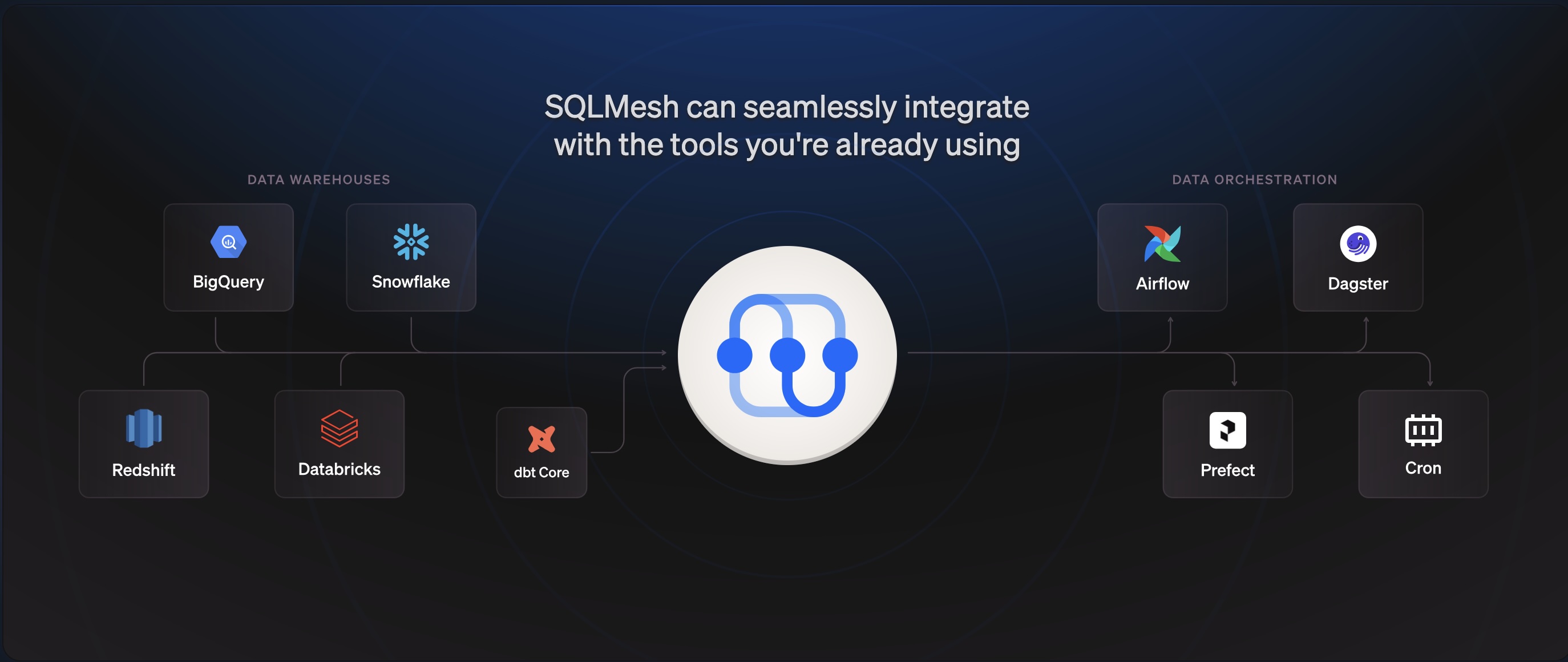
Key Features of SQLMesh
- Virtual Data Environments: Enables fast, isolated development and testing without duplicating large datasets. This reduces costs and risk, as changes can be promoted to production without redundant computation.
- Automatic DAG Generation: SQLMesh parses SQL and Python scripts to automatically create dependency graphs. Unlike dbt, it doesn’t require manual reference tagging, making onboarding and maintenance easier.
- Change Summaries & Guardrails: The platform highlights what changes will impact the data graph before deployment, helping you avoid breaking changes and unexpected side effects.
- Column-level Lineage: Offers granular visibility into how data moves and transforms through pipelines, easing debugging and compliance reporting.
- Smart Incremental Loads & Backfills: SQLMesh internally tracks what data segments need updating, making backfilling and incremental ingestion seamless and less error-prone.
- Integrated Testing & CI Support: Unit and integration tests are built-in and can run self-contained using DuckDB, providing high confidence in deployments.
- UI & Developer Experience: The web-based UI offers DAG visualization, in-line documentation, and introspection tools.
Summary: SQLMesh offers a dynamic, compiler-aware, and more automated approach, especially excelling in large, complex projects and when minimizing compute/storage costs is a priority. dbt is widely adopted, with a huge community and ecosystem, providing a stable declarative environment but with some rigidity and higher costs for large deployments.
Other Alternatives to SQLMesh
Dataform
- Focused on BigQuery users.
- Manages SQL transformations, dependency configs, and data quality assertions, and integrates with Git-based workflows.
- Best suited for Google Cloud-centric data teams.
AWS Glue
- A fully managed ETL tool for scalable data pipelines.
- Python-based and tightly integrated with the AWS stack.
- Has a higher learning curve but is suitable for serverless and large-scale data processing.
Matillion
- A no-code and low-code ETL/data transformation platform.
- Features drag-and-drop plus scripting for advanced transformations.
- Ideal for organizations that prefer minimal code and rapid pipeline deployment.
When to Choose SQLMesh
- If your team needs fast, cost-effective development environments without duplicating data.
- If you want semantic, column-level tooling and automatic dependency management.
- If your workflows require frequent, complex backfills or targeted changes.
- If you value built-in, integrated CI/CD and don’t want to manage extensive metadata stores or manual configuration for every change.
Conclusion
SQLMesh is a compelling modern option for data and analytics engineers who want to reduce operational costs, improve workflow safety, and speed up pipeline development. While dbt remains the industry standard due to its community and maturity, SQLMesh is rapidly becoming a favorite among teams with large, evolving, or highly experimental data environments. If you’re seeking automation and a superior developer experience, SQLMesh is well worth a trial run.
A new worst coder has entered the chat: vibe coding without code knowledge
Stack Overflow Blog’s latest post chronicles a non‑technical experiment with Bolt, an LLM‑powered tool that claims to bridge the gap for people without coding experience. The author, drawn from a Bay‑Area hackathon, creates a “toilet‑app” prototype via voice‑like prompts: “toilet application” → Bolt produces a functional front‑end in minutes, but the underlying code is messy, unorganized, and lacks security or unit tests. After running the app through a Bay‑Area engineer, Ryan uncovers glaring issues: absence of authentication, no data protection, and a high “productivity tax” where cleanup is inevitable. Peer feedback highlights structural problems—everything buried in ./project, inline TSX styling, missing descriptive class names, and no test suites. The article also shares a success story: a Stanford physicist who, through multiple LLMs, accelerated his learning curve ten‑fold, turning vibe‑coding into a stepping stone toward real‑world software development.

Expert take
From a data‑and‑tech perspective, the experiment illustrates the double‑edged nature of vibe‑coding tools. They enable rapid prototyping and democratize coding, yet they produce fragile, insecure, and maintenance‑heavy artifacts. The 66 % “productivity tax” figure underscores a real bottleneck: developers still need to intervene post‑generation. For serious projects—especially those handling personal data—vibe‑coding alone is insufficient; a seasoned engineer’s review remains essential.
Reference: Original article on Stack Overflow Blog
VeriTrail: Detecting Hallucination and Tracing Provenance in Multi‑Step AI Workflows
A recent Microsoft Research blog by Dasha Metropolitansky (Published Aug 5 2025) introduces VeriTrail, a pioneering method for closed‑domain hallucination detection that also delivers traceability across any number of generative steps. Unlike conventional detectors that compare a single LM output to source text, VeriTrail works on a directed acyclic graph (DAG) representing every intermediate and final output. By extracting claims from the final response and verifying them in reverse order, the system assigns a verdict (“Fully Supported,” “Not Fully Supported,” or “Inconclusive”) and produces an evidence trail—sentences, node IDs, and summaries—that lets users see exactly where a claim originates.
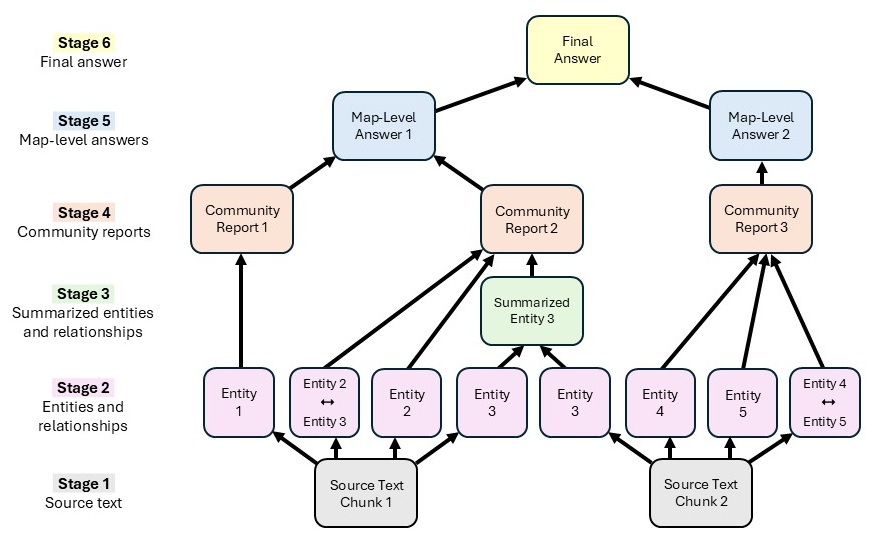
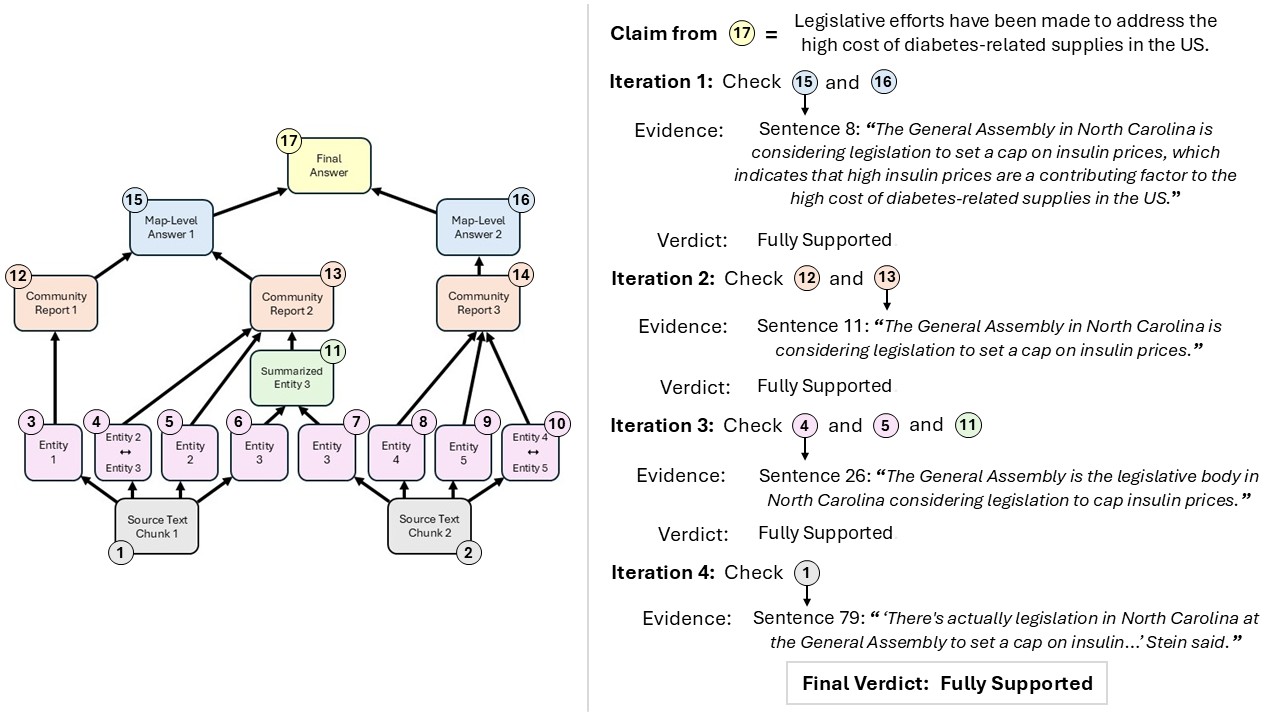
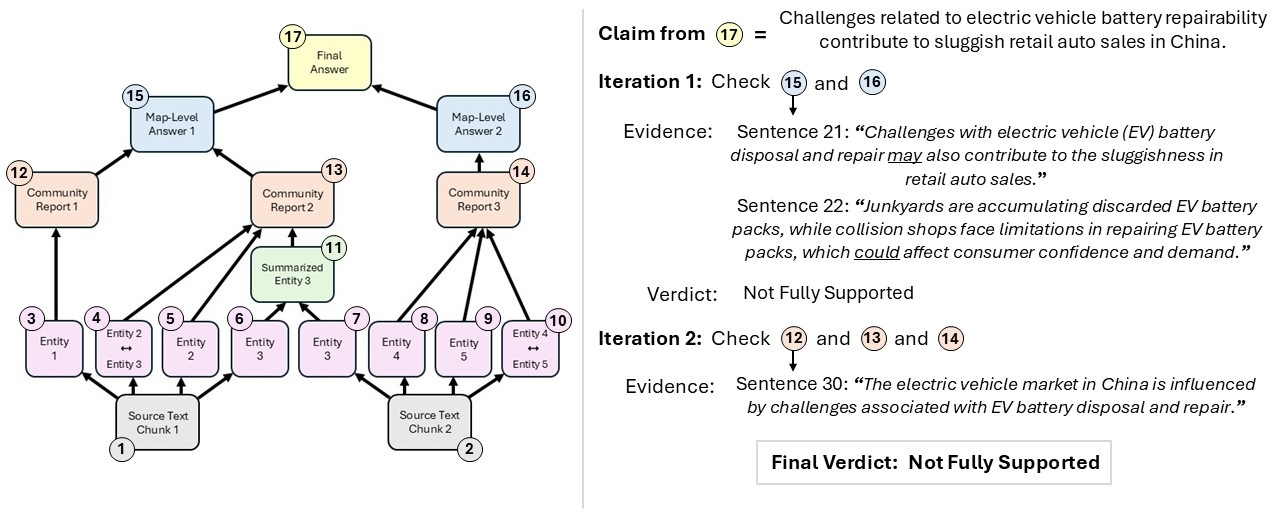
Figures illustrate VeriTrail’s workflow: from DAG construction and claim extraction to evidence tracing and verdict assignment. Each step visualizes how the system detects hallucinations and provides transparent provenance for AI-generated outputs.
Key findings: on two diverse datasets (hierarchical summarization of long fiction novels and GraphRAG over news articles) and across several language models (AlignScore, INFUSE, Gemini 1.5 Pro, GPT‑4.1 mini, and others), VeriTrail outperformed baseline hallucination detectors. It was especially strong in the most complex graphs (average 114,368 nodes). Moreover, its traceability uncovers the introduction point of hallucinated content, providing transparency that aids debugging and trust.
For deeper technical details, see the full paper VeriTrail: Closed‑Domain Hallucination Detection with Traceability.
Reference: Microsoft Research Blog Published Paper
Real‑Time Collaboration Tools Redefining Developer Workflows
In a landscape where a single context switch can steal up to 15 minutes of focus, the author argues that real‑time collaboration is the next frontier for productivity. They outline five tools that blend synchronous immediacy with asynchronous structure, and present statistics showing how integrating these can slash context‑switching time.

Key Tools
- VS Code Live Share – IDE‑integrated pair programming that shares code, terminal, and debugging sessions without leaving VS Code.
- Replit – Cloud‑hosted development environment with a native “multiplayer” mode, letting teams run, debug, and prototype together like Google Docs.
- tldraw – Minimalist, open‑source whiteboard offering an infinite canvas for real‑time drawing, diagramming, and embedding in any web app.
- LiveKit – Open‑source RTC infrastructure that can be self‑hosted, providing flexible APIs for custom real‑time applications.
- Tencent RTC – A high‑quality real‑time communication engine used by top‑tier DevOps platforms; it powers smooth collaboration in tools such as VS Code Live Share and Figma.
Impact
- Teams using Tencent RTC report a 50 % reduction in context switching.
- Time to solve complex problems drops by 35 %.
- The core of 2025 developer productivity shifts from solo coding speed to collaborative efficiency.
Expert Take: Adopting ready‑made tools like Live Share or building with an engine such as Tencent RTC can transform a team’s workflow, turning meetings into instant pair‑programming sessions and cutting overhead.
Reference: Read more
How OpenTelemetry is standardizing DevOps observability
OpenTelemetry (OTel) is an open‑source observability framework that standardizes the generation, collection, processing, and export of telemetry data—metrics, logs, and traces. Think of it as a universal language for your observability needs, backed by the Cloud Native Computing Foundation (CNCF) alongside Kubernetes.

Core observability workflow (as described):
- Extract data (metrics, logs, traces) from different parts of systems.
- Record the data.
- Analyze/correlate the data to derive insights.
To enable extraction, software must expose telemetry in a protocol that observability tools can consume—this is the instrumenting process. OTel supplies SDKs that instrument applications, allowing telemetry to be sent to multiple platforms.
Prior to OTel, the landscape was fragmented and frustrating. OTel addresses these gaps by:
- Providing flexibility, control, and efficiency.
- Gaining enthusiastic support from the open‑source community and major observability vendors, ensuring a vendor‑agnostic future.
Best practices for maximizing OTel:
- Adopt SDKs for instrumentation early.
- Contribute to beta SDKs to stay ahead of industry trends.
Although still evolving, OTel is a foundational shift toward standardized, vendor‑agnostic observability in DevOps.
Reference: Medium article
ETL Patterns: Incremental and Full Data Refresh
The Extract-Transform-Load (ETL) pattern, a foundational concept in data engineering, emerged in the early 1990s to centralize and organize massive, disparate datasets for business intelligence. Early ETL tools like Informatica and IBM DataStage automated complex workflows, extracting, cleaning, transforming, and loading data into a centralized data warehouse. This established ETL as the industry standard in modern data warehousing. However, as data volumes grew and the need for near-real-time insights increased, the original ETL paradigm evolved. Modern data pipelines now distinguish between a full data refresh and an incremental data refresh.
Full Data Refresh:
- Replaces all data in the target system with a fresh load of the entire source dataset.
- Best for initial data loads, smaller datasets, and scenarios where simplicity and consistency are paramount.
Incremental Data Refresh:
- Updates only the new or changed records since the last successful ETL run.
- Tracks changes using a timestamp or unique key, extracts new or modified data, and merges it with the existing dataset.
- Best for large, frequently updated datasets and applications requiring near-real-time data availability, where processing the entire dataset is too slow and resource-intensive.
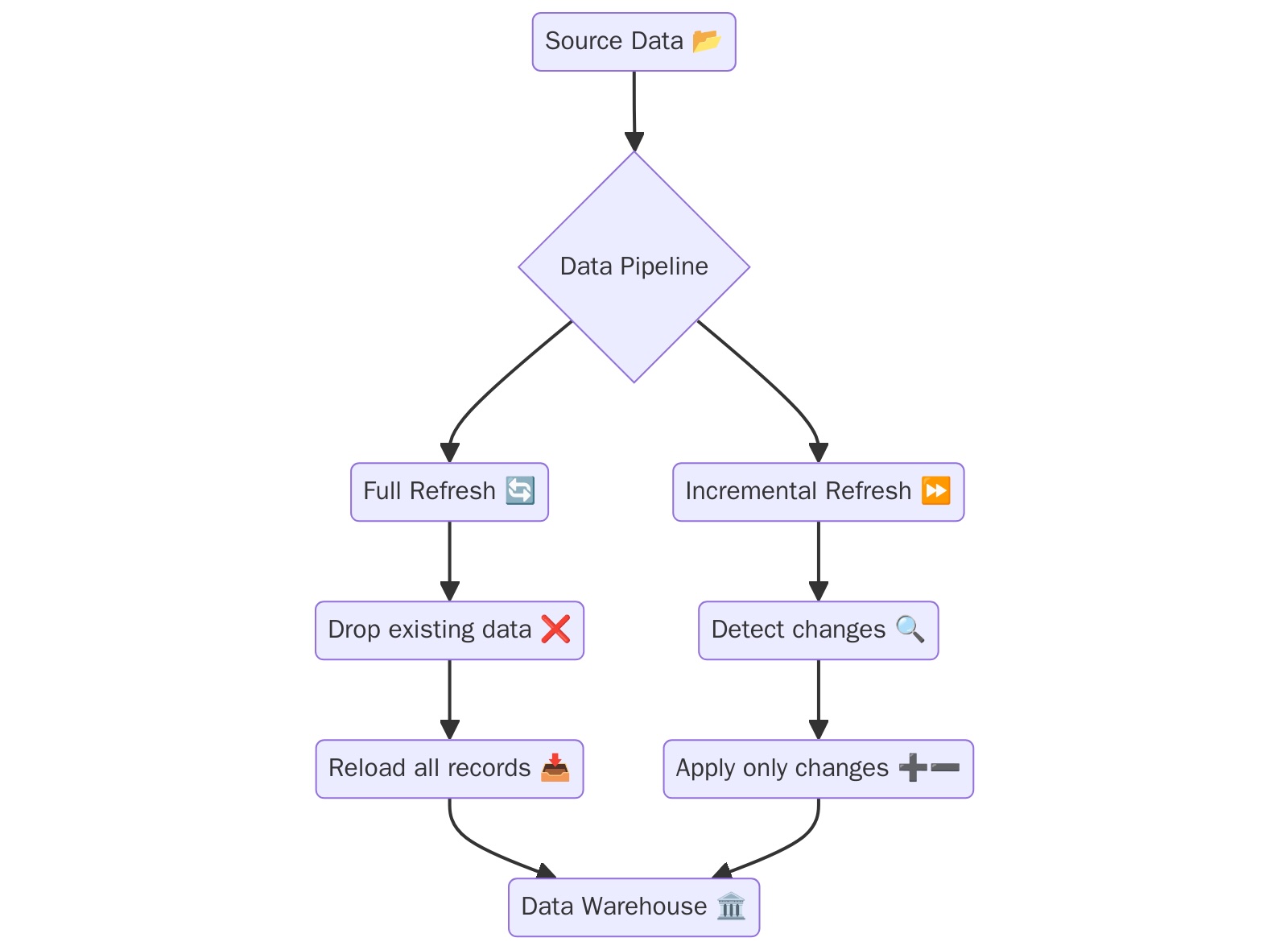
Expert Take: The Continuing Relevance of Both Patterns
While many modern data platforms prioritize incremental, real-time processing, the Full Data Refresh pattern remains valuable for static, less frequently updated datasets. For instance, a nightly batch job to update a dimension table of country codes is a perfect use case for a full refresh.
Conversely, the sheer scale of today’s data necessitates Incremental Data Refresh. An e-commerce platform processing millions of sales transactions daily would be overwhelmed by a full refresh. An incremental approach adds only the latest transactions, ensuring the data warehouse stays current without overwhelming the system.
The choice of ETL pattern depends on business requirements, technical constraints, and operational needs. Modern data engineers must understand both methods to design efficient, reliable, and scalable pipelines for today’s and tomorrow’s challenges.
Learning Loop

Originals by Adam Grant explores how non-conformists drive creativity and change, detailing strategies for championing new ideas, overcoming fear, and fostering innovation in work and life. The book emphasizes that originality isn’t just about having ideas but also about how actively and bravely one pushes those ideas forward.
Grit by Angela Duckworth argues that sustained passion and perseverance—rather than talent alone—are the keys to high achievement. Duckworth uses scientific research and real-life stories to show that grit is essential for long-term success and can be cultivated in individuals through consistent effort.
This Is Marketing by Seth Godin reframes marketing as an act of empathy and service, advocating for targeting the smallest viable audience and crafting authentic stories that solve real customer problems. Godin emphasizes that modern marketing is about creating genuine value and fostering meaningful change, rather than relying on mass advertising or manipulation.
📺 YouTube Channel Seattle Data Guy (114k Subscribers)
Explore FREE Learning Content on Model Context Protocol (MCP) For Beginners By Microsoft Developer
Final Thoughts
The modern engineering landscape is a tug-of-war between rapid automation and the critical need for quality, trust, and maintainability. SQLMesh exemplifies this by automating complex data pipeline tasks—like DAG generation and backfills—to reduce developer friction and operational costs. However, as the “vibe coding” experiment reveals, unchecked automation can lead to “fragile, insecure, and maintenance-heavy” artifacts. This underscores the importance of tools to build in guardrails and quality assurance to prevent a similar “productivity tax” in data infrastructure.
The VeriTrail project further highlights this core concern, showing the necessity of tracing the provenance of outputs to detect hallucinations and build trust in AI systems. This same need for transparency applies to data engineering, where SQLMesh’s column-level lineage provides a verifiable audit trail for data transformations. Finally, frameworks like OpenTelemetry standardize the observability required to manage and understand these increasingly complex, automated workflows, ensuring that the push for efficiency doesn’t come at the cost of reliability.